Recently I’ve seen a thread on Twitter regarding distributed tracing systems. I recognise that sometimes it’s an underestimated topic, so I thought to write a short and introductory article about it…
Scrolling my TL, I’ve seen a thread by Jaana Dogan regarding distributed tracing systems; under that thread, I’ve read many people asking about it or just interested in that topic, so here we go.

What is distributed tracing?
One of the advantages of having a monolithic application is that we don’t need to worry too much about tracing our incoming requests because everything is self-contained.
However, when a request comes into a microservice, that could result in a cascading chain of calls to various other services, and there the tracing could become a very complex task.
Distributed tracing allows the logs to span servers, not only through multiple instances of a single service but through multiple instances of multiple services establishing a correlation between them.
By the book, the tracing system should allow scalability and have low overhead and application-level transparency. Ideally, it should enable quick analysis of the tracing data.
Practical Example
Let’s see a diagram of what can happen in a real use case scenario
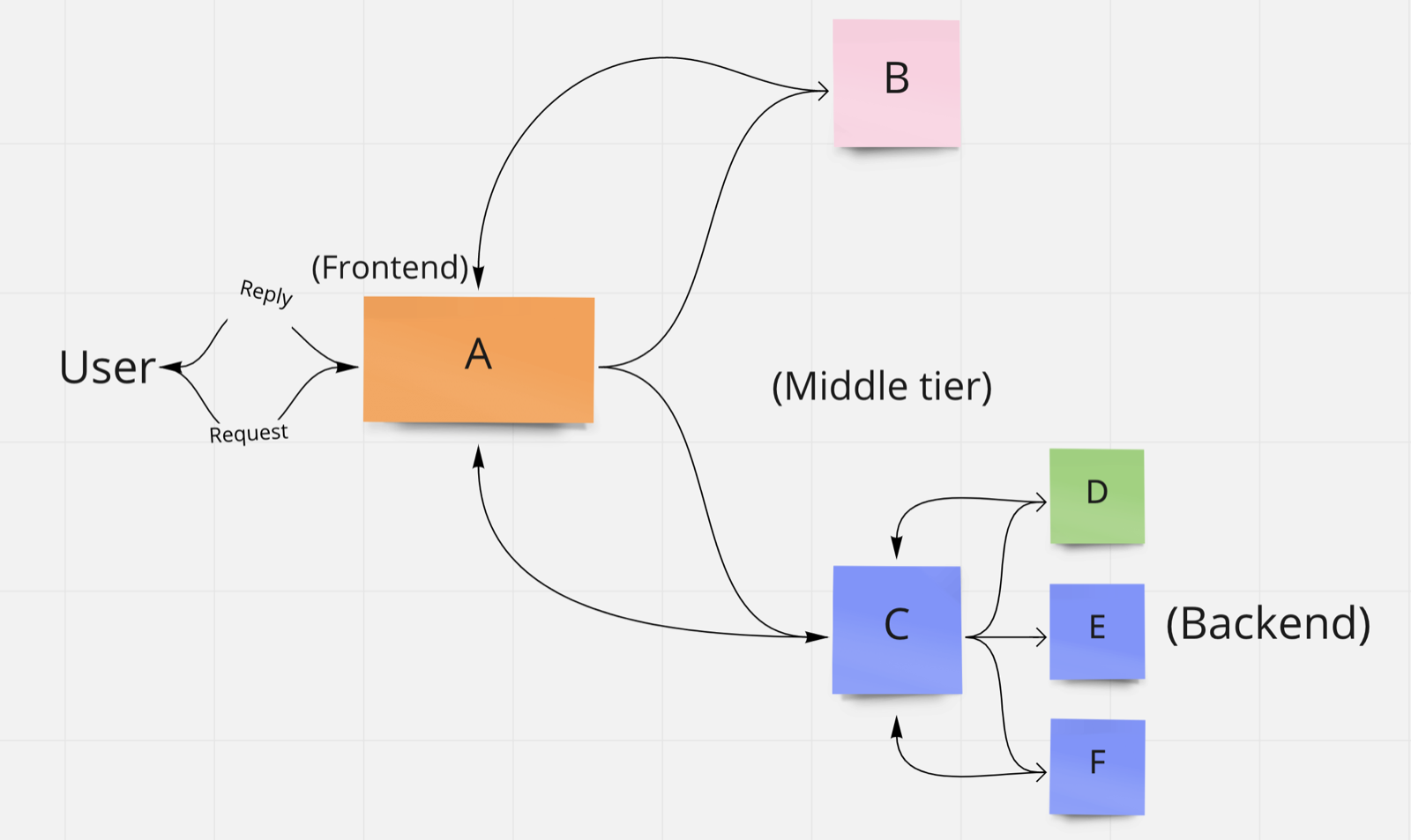
To track and monitor this entire request flow, considering that we have multiple instances of the web app and other services running, an origination id is needed that spans the request as the whole flow.
Each step must generate and use span ids to helps us to considers each step as part of a bigger request flow.
For instance:
A user requests a webpage, so we will generate an Origination Id: 123 and a Span Id: 1, then the page calls another service to get the profile detail, so we are going to have an Origination Id: 123 and a Span Id: 2, and so on.
This is important to trace logs in a way to help us to reverse a sequence diagram from the available data for any request. Having enough context it will be simpler and faster, helping us to react quickly when needed.
How to implement it
The implementation is relatively straightforward. For every incoming request, examine the HTTP headers. If there is a trace id, we know we are already tracing it down; if there isn’t, create a new one. Always create a new span id and then make the trace and span context available to our code to add metrics and helpful information for later.
I really recommend not reinvent the wheel. Nowadays, there are many already well-known solutions, and most of them work very well for most scenarios.
References
Distributed tracing is essential for troubleshooting microservices applications; most modern distributed tracing solutions are based on the Google Dapper Whitepaper that I suggest reading.
Nowadays, observability is one of the most important things; it helps us identify problems and act in time. Definitely, going deeper on this topic is a must to whoever wants to be founded ready.